Gain/Effort planning for my projects
My open-source journey got to the stage, where the backlog grows much faster than I am able to process. Not every good idea is worth pursuing, not every RFE can be implemented, and not every bug can be fixed. I needed to start prioritizing.
Planning
In my team at work, we use capacity-based planning (to guesstimate how many tasks can be done within one sprint) and schedule tasks into the following abstract timeframes - In progress, in three months, in two years, and someday in the future (which is an euphemism for probably never). I don’t need any of these for my personal projects. There is no team, no sprints, and basically no deadlines.
I work on my personal projects in short bursts of time sprinkled throughout my evenings, weekends, and holidays. For me, the whole planning can be reduced to - Which task from any of my projects will move the project noticeably forward, while being easy enough that it can be sandwiched between my worktime?
I always liked how Fedora Infra does their planning. They set two labels for each ticket. One indicates how much will be gained by completing the ticket and the other indicates how much trouble it will cause. Now, I don’t like the word trouble. Does it mean how much trouble is caused by the missing feature? Or will potentially be caused? Probably not. I suppose it represents how much trouble will somebody have to undergo to implement it. There is a better word for that - effort.
The Packit team uses a slightly more complex version of this system. Instead of effort, they track complexity (as in easy fix, single task, or epic), and they add another factor to the equation by differentiating between gain and impact. I don’t need any of that for my personal projects.
I believe this kind of planning is not revolutionary and is widely known as the Value/Effort matrix, Impact/Effort grid, 2x2 prioritization, etc. And yes, I’ve read all the articles saying it is obsolete, flawed, misleading, harmful, dangerous, and incorrect. My proof to the contrary is the Fedora Infra team which is a stellar example of how to sustain an unbelievable amount of work in a very limited number of people, and the Packit team, which brought the most innovations to RPM packaging in years.
Labels
All of my projects live on GitHub so I decided to go with
effort/low, effort/medium, and effort/high labels for representing the
estimated effort and gain/low, gain/medium, and gain/high for representing
the imagined gain. It would be annoying to set up the labels for each repository
manually. Use this script to create them.
Quick wins
It is straightforward to pick the next task to work on - whatever is
effort/low AND gain/high. Everybody knows how to filter such tickets within a
GitHub repository. However, what is far more interesting is searching such
tickets across all your repositories at once. For that, we can use the gh
command-line tool:
gh search issues \
-R frostyx/tracer \
-R frostyx/fedora-sponsors \
-R frostyx/fedora-review-service \
-R frostyx/dotfiles \
-R frostyx/helm-ement \
-R rpm-software-management/tito \
-R rpm-software-management/fedora-distro-aliases \
--state open \
--label effort/low \
--label gain/high
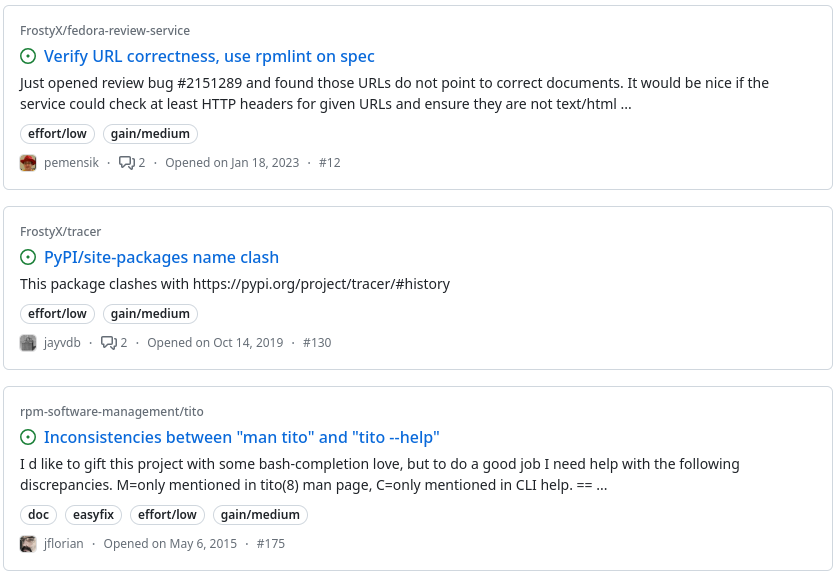
The output looks like this:

Don’t like the command line very much? Use the -w parameter
to generate a GitHub search query and open it in the web browser.
Not triaged issues
It is a good idea to periodically check what issues slipped through the cracks and weren’t given any gain or effort tags.
gh search issues \
-R frostyx/tracer \
-R frostyx/fedora-sponsors \
-R frostyx/fedora-review-service \
-R frostyx/dotfiles \
-R frostyx/helm-ement \
-R rpm-software-management/tito \
-R rpm-software-management/fedora-distro-aliases \
--state open \
-- \
-label:effort/low \
-label:effort/medium \
-label:effort/high\
-label:gain/low \
-label:gain/medium \
-label:gain/high
Do you have any tips or tricks for prioritization and time management when it comes to personal open-source projects?