Rebuilding the entire RubyGems in Copr
We took all 166 699 packages from RubyGems.org and rebuilt them in Copr. Let’s explore the results together.
Success rate
From the 166 699 Gems hosted on RubyGems.org, 98 816 of them were successfully built in Copr for Fedora Rawhide. That makes a 59.3% success rate. For the rest of them, it is important to distinguish in what build phase they failed. Out of 67 883 failures, 62 717 of them happened while converting their Gemfile into spec and only 5 166 when building the actual RPM packages. It means that if a Gem can be properly converted to a spec file, there is a 95% probability for it to be successfully built into RPM.
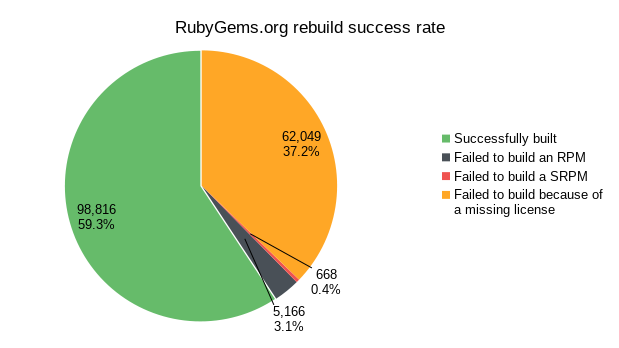
By far, the majority of failures were caused by a missing license field for the particular Gems. There is likely nothing wrong with them, and technically, they could be built without any issues, but we simply don’t have legal rights to do so. Therefore such builds were aborted before even downloading the sources. This affected 62 049 packages.
More stats
All Gems were rebuilt within the @rubygems/rubygems
Copr project for fedora-rawhide-x86_64 and fedora-rawhide-i386.
We submitted all builds at once, starting on Sep 11, 2021, and the whole rebuild was finished on Oct 17, 2021. It took Copr a little over a month, and within that time, the number of pending builds peaked at 129 515.
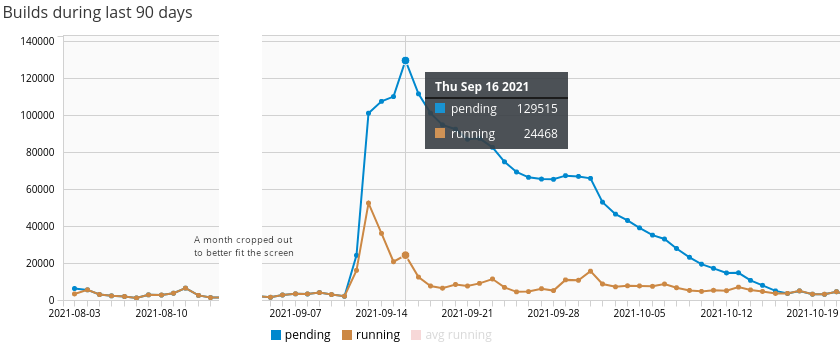
The number of running builds doesn’t represent 24 468 running
builds at once but rather the number of builds that entered the
running state on that day. It doesn’t represent Copr throughput
accurately though, as we worked on eliminating performance issues
along the way. A similar mass rebuild should take a fraction of the
time now.
The resulting RPM packages ate 55GB per chroot, therefore 110GB in total. SRPM packages in the amount of 640MB were created as a byproduct.
The repository metadata has 130MB and it takes DNF around 5 minutes on my laptop (Lenovo X1 Carbon) to enable the repository and install a package from it for the first time (because it needs to create a cache). Consequent installations from the repository are instant.
In perspective
To realize if those numbers are anyhow significant or interesting, I think we need to compare them with other repositories.
| # | @rubygems/rubygems | Fedora Rawhide (F36) | EPEL8 |
|---|---|---|---|
| The Number of packages | 98 816 | 34 062 | 4 806 |
| Size per chroot | 55GB | 83GB | 6.7GB |
| Metadata size | 130MB | 61MB | 11MB |
dnf makecache |
~5 minutes | ~22 seconds | 1 second |
Motivation
What was the point of this experiment anyway?
The goal was to rebuild all packages from a third-party hosting service that is specific to some programming language. There was no particular reason why we chose RubyGems.org among other options.
We hoped to pioneer this area, figure out the pain points, and make it easier for others to mass-rebuild something that might be helpful to them. While doing so, we had the opportunity to improve the Copr service and test the performance of the whole RPM toolchain against large repositories.
There are reasons why to avoid installing packages directly via gem,
pip, etc, but that’s for a whole other discussion. Let me just
reference a brief answer from Stack Overflow.
Internals
Surprisingly enough, the mass rebuild itself wasn’t that
challenging. The real work manifested itself as its consequences
(unfair queue, slow createrepo_c, timeouts everywhere). Rebuilding
the whole RubyGems.org was as easy as:
-
Figuring out a way to convert a Gemfile into spec. Thank you, gem2rpm!
-
Figuring out how to submit a single Gem into Copr. In this case, we have built-in support for gem2rpm (see the documentation), therefore it was as easy as
copr-cli buildgem .... Similarly, we have built-in support for PyPI. For anything else, you would have to utilize the Custom source method (at least until the support for such tool/service is built into Copr directly). -
Iterating over the whole RubyGems.org repository and submitting gems one by one. A simple script is more than sufficient, but we utilized copr-rebuild-tools that I wrote many years ago.
-
Setting up automatic rebuilds of new Gems. The release-monitoring.org (aka Anitya) is perfect for that. We check for new RubyGems.org updates every hour, and it would be trivial to add support for any other backend. Thanks to Anitya, the repository will always provide the most up-to-date packages.
Takeaway for RubyGems
If you maintain any Gems, please make sure that you have properly set their license. If you develop or maintain any piece of software, for that matter, please make sure it is publicly known under which license it is available.
Contrary to the common belief, unlicensed software, even though publicly available on GitHub or RubyGems, is in fact protected by copyright, and therefore cannot be legally used (because a license is needed to grant usage rights). As such, unlicensed software is neither Free software nor open source, even though technically it can be downloaded and installed by anyone.
If I could have a wishful message towards RubyGems.org maintainers, please consider placing a higher significance on licensing and make it required instead of recommended.
For the reference, here is a list of all 65 206 unlicensed Gems generated by the following script (on Nov 14 2021). https://gist.github.com/FrostyX/e324c667c97ff80d7f145f5c2c936f27#file-rubygems-unlicensed-list
#!/bin/bash
for gem in $(gem search --remote |cut -d " " -f1) ; do
url="https://rubygems.org/api/v1/gems/$gem.json"
metadata=$(curl -s $url)
if ! echo $metadata |jq -e '.licenses |select(type == "array" and length > 0)'\
>/dev/null; then
echo $metadata |jq -r '.name'
fi
done
There are also 3 157 packages that don’t have their license field set on RubyGems.org but we were able to parse their license from the sources. https://gist.github.com/FrostyX/e324c667c97ff80d7f145f5c2c936f27#file-rubygems-license-only-in-sources-list
Takeaway for DNF
It turns out DNF handles large repositories without any major difficulties. The only inconvenience is how long it takes to create its cache. To reproduce, enable the repository.
dnf copr enable @rubygems/rubygems
And create the cache from scratch. It will take a while (5 minutes for the single repo on my machine).
dnf makecache
I am not that familiar with DNF internals, so I don’t really know if this is something that can be fixed. But it would certainly be worth exploring if any performance improvements can be done.
Takeaway for createrepo_c
We cooperated with createrepo_c developers on multiple performance
improvements in the past, and these days createrepo_c works
perfectly for large repositories. There is nothing crucial left to do,
so I would like to briefly describe how to utilize createrepo_c
optimization features instead.
First createrepo_c run for a large repo will always be slow, so just
get over it. Use the --workers parameter to specify how many threads
should be spawned for reading RPMs. While this brings a significant
speedup (and cuts the time to half), the problem is, that even listing
a large directory is too expensive. It will take tens of minutes.
Specify the --pkglist parameter to let createrepo_c generate a new
file containing the list of all packages in the repository. It will
help us to speed up the consecutive createrepo_c runs. For them,
specify also --update, --recycle-pkglist, and --skip-stat. The
repository regeneration will take only a couple of seconds
(437451f).
Takeaway for appstream-builder
On the other hand, appstream-builder takes more than 20 minutes to
finish, and we didn’t find any way to make it run faster. As a
(hopefully) temporary solution, we added a possibility to disable
AppStream metadata generation for a given project
(PR#742), and recommend owners of large projects to do so.
From the long-term perspective, it may be worth checking out whether
there are some possibilities to improve the appstream-builder
performance. If you are interested, see upstream issue
#301.
Takeaway for Copr
The month of September turned into one big stress test, causing Copr to be temporarily incapacitated but helping us provide a better service in the long-term. Because we never had such a big project in the past, we experienced and fixed several issues in the UX and data handling on the frontend and backend. Here are some of them:
- Due to periodically logging all pending builds, the apache log skyrocketed to 20GB and consumed all available disk space (PR#1916).
- Timeouts when updating project settings (PR#1968)
- Unfair repository locking caused some builds unjustifiably long to be finished (PR#1927).
- We used to delegate pagination to the client to provide a better user experience (and honestly, to avoid implementing it ourselves). This made listing builds and packages in a large project either take a long time or timeout. We switched to backend pagination for projects with more than 10 000 builds/packages (PR#1908).
- People used to scrap the monitor page of their projects but that
isn’t an option anymore due to the more conservative pagination
implementation. Therefore we added proper support for project
monitor into the API and
copr-cli(PR#1953). - The API call for obtaining all project builds was too slow for large
projects. In the case of the
@rubygems/rubygemsproject, we managed to reduce the required time from around 42 minutes to 13 minutes (PR#1930). - The
copr-clicommand for listing all project packages was too slow and didn’t continuously print the output. In the case of the@rubygems/rubygemsproject, we reduced its time from around 40 minutes to 35 seconds (PR#1914).
Let’s build more
To achieve such mass rebuild, no special permissions, proprietary tools, or any requirements were necessary. Any user could have done it. In fact, some of them already did.
- iucar/cran
- @python/python3.10
- PyPI rebuild is being worked on by Karolina Surma
But don’t be fooled, Copr can handle more. Will somebody try Npm, Packagist, Hackage, CPAN, ELPA, etc? Let us know.
I would suggest starting with Copr Mass Rebuilds documentation.